The Backlog
A live state machine, not a task list
Every backlog item moves through five stages with automated transitions. Agents claim work, the system tracks conflicts, and the human sees a real-time view of what every agent is doing and why.
Intake
15
Needs acceptance criteria
→
Ready
8
AC verified, work package generated
→
In Progress
1
Agent claimed, executing
→
Review
2
Eval runs first, human only if ambiguous
→
Done
8
Validated, merged, session archived
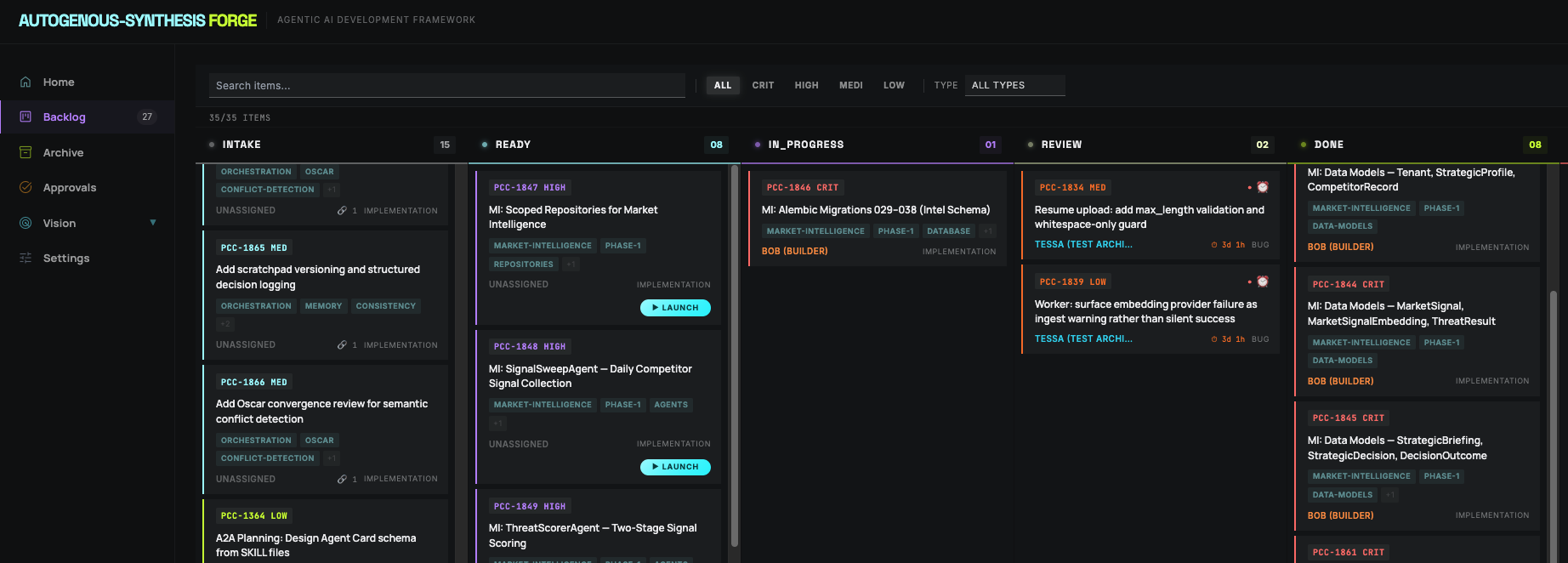
FORGE DASHBOARD · LIVE BACKLOG · 35 ITEMS · http://localhost:5175
Acceptance Criteria are Machine-Verifiable
Every backlog item in the ready state includes a table of Ideal State Criteria — binary, pass/fail conditions with explicit verification methods. No "it should work" or subjective sign-offs.
Example ISC Table
| # | Criterion | Verified how | |---|-----------------------------------|----------------------| AC1 Migrations 029–038 applied cleanly alembic current == head AC2 All 6 new models importable pytest -k test_models AC3 Rollback to 028 succeeds alembic downgrade -1
The HTTP API Is the Contract
All state changes go through a single HTTP API server. No UI required. Agents make REST calls; the dashboard reflects state in real time via WebSocket. The API has atomic writes, 10-retry exponential backoff, and file-lock conflict detection.
Agent claiming a ticket
curl -X PATCH http://localhost:5176/api/backlog/PCC-1846 \ -H "Content-Type: application/json" \ -d '{ "status": "in_progress", "assignedAgent": "bob" }'